Googles Gemma 4 AI erhält einen dreifachen Geschwindigkeitsschub

Die Gemma 4 AI-Modelle von Google verfügen jetzt über die Multi-Token Prediction-Technologie und bieten eine dreimal schnellere Leistung. Erfahren Sie, wie spekulative Dekodierung die lokale KI-Verarbeitung verbessert.
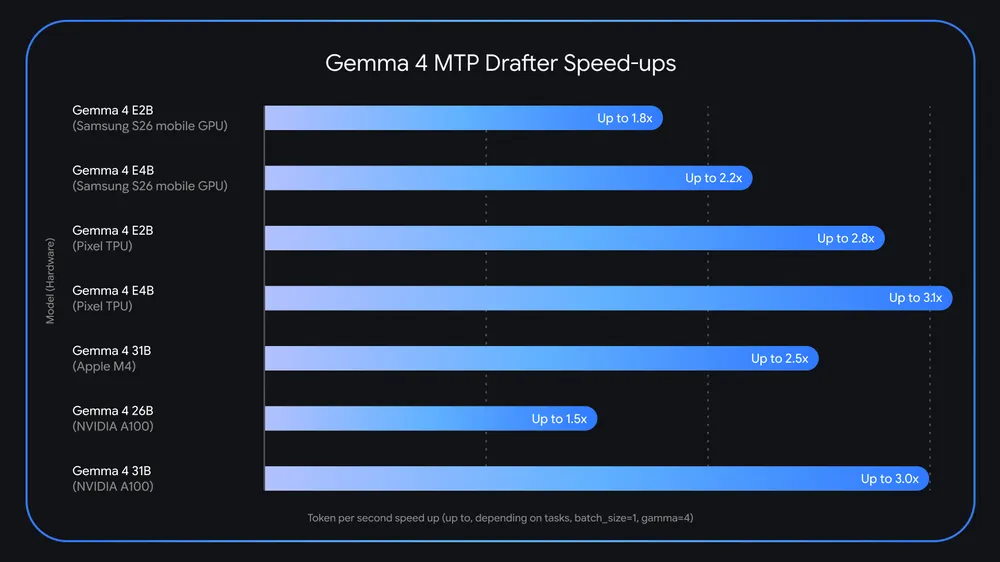
Googles Gemma-4-KI-Modelle haben gerade eine bedeutende Leistungssteigerung erhalten, die die Herangehensweise von Entwicklern an die Edge-KI-Bereitstellung verändern könnte. Der Suchriese stellte Anfang des Frühlings seine Gemma 4 Open-Source-KI-Modelle mit beeindruckenden Fähigkeiten vor, die für die lokale Ausführung konzipiert sind, und jetzt geht das Unternehmen mit der bahnbrechenden Multi-Token Prediction (MTP)-Technologie noch einen Schritt weiter. Dieser innovative Fortschritt verspricht, die Inferenzgeschwindigkeit zu revolutionieren und möglicherweise eine bis zu dreimal schnellere Token-Generierung im Vergleich zu herkömmlichen Ansätzen zu ermöglichen. Die Einführung von MTP-Draftern stellt einen großen Fortschritt dar, um leistungsstarke KI für Edge-Computing-Szenarien zugänglich und effizient zu machen.
Im Mittelpunkt dieser Leistungsverbesserung steht eine hochentwickelte Technik namens spekulative Dekodierung, die die Art und Weise, wie KI-Modelle Text und andere Ausgaben generieren, grundlegend verändert. Anstatt jeweils einen Token nacheinander vorherzusagen, nutzt das Multi-Token-Vorhersagesystem fortschrittliche Algorithmen, um mehrere zukünftige Token gleichzeitig intelligent vorherzusagen. Dieser Ansatz ermöglicht es dem System, „nach vorne zu schauen“ und fundierte Vermutungen darüber anzustellen, was im Generierungsprozess als nächstes kommt, wodurch der Rechenaufwand und die Latenz, die mit der herkömmlichen Token-für-Token-Generierung verbunden sind, drastisch reduziert werden. Das Forschungsteam von Google hat diese experimentellen Modelle so entwickelt, dass sie nahtlos mit der Architektur von Gemma zusammenarbeiten, sodass Entwickler diesen Geschwindigkeitsvorteil nutzen können, ohne dass wesentliche Änderungen an ihren bestehenden Arbeitsabläufen erforderlich sind.
Die Architektur der Gemma 4-Modelle basiert auf derselben grundlegenden Technologie, die auch dem hochmodernen Gemini-KI-System von Google zugrunde liegt, das das fortschrittlichste große Sprachmodell-Angebot des Unternehmens darstellt. Während Gemini jedoch für den Betrieb in Googles proprietären Rechenzentren und benutzerdefinierter Hardware optimiert ist, wurde Gemma 4 speziell für den effizienten Betrieb auf lokaler Hardware und Edge-Geräten abgestimmt und verfeinert. Diese Lokalisierungsstrategie bedeutet, dass Entwickler nicht mehr auf die Cloud-Infrastruktur angewiesen sind oder sensible Daten an Remote-Server senden müssen, was die Kalkulation für datenschutzbewusste Organisationen und solche mit strengen Daten-Governance-Anforderungen grundlegend ändert. Der technische Ansatz zeigt Googles Engagement für die Demokratisierung fortschrittlicher KI-Technologie in verschiedenen Computerumgebungen.
Der Infrastrukturhintergrund von Google beeinflusst eindeutig das Design von Gemma 4, da das Unternehmen seine KI-Systeme traditionell so optimiert hat, dass sie benutzerdefinierte TPU-Chips nutzen, die in riesigen Clustern mit außergewöhnlichen Verbindungsgeschwindigkeiten und Speicherbandbreite arbeiten. Diese spezialisierten Prozessoren, die im Laufe der Jahre der maschinellen Lernforschung von Google entwickelt wurden, bieten enorme Rechenvorteile in Rechenzentrumsumgebungen, in denen Gemini sein volles Potenzial ausschöpft. Für Gemma ändert sich jedoch die technische Philosophie dramatisch: Die Modelle sind so konzipiert, dass sie effizient auf Standard-Hardware für Endverbraucher funktionieren. Ein einziger Hochleistungs-KI-Beschleuniger kann selbst die größten Gemma 4-Modelle erfolgreich mit voller Präzision betreiben und liefert respektable Inferenzgeschwindigkeiten ohne exotische Spezialhardware.
Für Entwickler, die mit bescheideneren Hardwarebudgets arbeiten, bieten Quantisierungstechniken einen zusätzlichen Weg zur effektiven Bereitstellung von Gemma 4. Die Quantisierung verringert die numerische Präzision von Modellgewichtungen und -aktivierungen und führt typischerweise zu einer Konvertierung von 32-Bit-Gleitkommaformaten in Formate mit geringerer Genauigkeit wie 8-Bit-Ganzzahlen oder 4-Bit-Werte. Dieser Komprimierungsansatz reduziert nicht nur den Speicherbedarf, sondern beschleunigt auch die Berechnung, sodass selbst GPUs der Verbraucherklasse umfangreiche KI-Modelle verarbeiten können. In Kombination mit der Multi-Token-Vorhersage-Verbesserung könnten quantisierte Gemma-4-Modelle bemerkenswerte Leistungsmerkmale auf Laptops, Edge-Servern und anderen ressourcenbeschränkten Umgebungen liefern. Diese Zugänglichkeit stellt einen Wendepunkt für den lokalen KI-Einsatz dar und beseitigt traditionelle Hindernisse, die in der Vergangenheit fortschrittliche KI-Funktionen auf gut ausgestattete Organisationen beschränkt haben.

Datenschutzerwägungen haben seit langem das Interesse an Edge-KI-Systemen vorangetrieben, und Gemma 4 mit MTP-Technologie verstärkt dieses Wertversprechen erheblich. Indem diese Modelle erweiterte KI-Inferenz direkt auf lokaler Hardware ermöglichen, entfällt die Notwendigkeit, sensible Daten an Cloud-Dienste zu übertragen, die von Google oder konkurrierenden Anbietern betrieben werden. Dieser Architekturansatz erweist sich als besonders wertvoll für Organisationen, die vertrauliche Geschäftsinformationen, durch HIPAA-Vorschriften geschützte Gesundheitsdaten oder personenbezogene Daten verarbeiten, die der DSGVO und ähnlichen Datenschutzrahmen unterliegen. Die Möglichkeit, anspruchsvolle KI-Aufgaben auszuführen, ohne die lokale Computerumgebung zu verlassen, erfüllt regulatorische Anforderungen und reduziert gleichzeitig die Latenz und verbessert das Benutzererlebnis durch schnellere Reaktionszeiten.
Die Entscheidung von Google, Gemma 4 unter der Apache 2.0 Open-Source-Lizenz erneut zu lizenzieren, stellt einen weiteren wichtigen Gesichtspunkt für Entwickler und Organisationen dar, die die Einführung prüfen. Die Apache 2.0-Lizenz bietet im Vergleich zur ursprünglichen benutzerdefinierten Gemma-Lizenz von Google deutlich mehr Freizügigkeit und bietet umfassendere Freiheiten für die kommerzielle Nutzung, Änderung und Verbreitung. Durch diese Änderung wird Gemma 4 an den Best Practices der Branche für Open-Source-KI ausgerichtet und die Modelle als wirklich zugängliche Ressourcen für die breitere Entwicklergemeinschaft positioniert. Die Lizenzänderung beseitigt wirksam rechtliche Unklarheiten, die früher möglicherweise zu komplizierten kommerziellen Einsätzen oder erheblichen Änderungen an den Basismodellen geführt haben. Für Unternehmen, die ihre KI-Infrastrukturstrategie evaluieren, verbessert diese freizügigere Lizenzlandschaft die Risikokalkulation im Zusammenhang mit der Einführung von Gemma erheblich.
Die technische Innovation der Multi-Token-Vorhersage basiert auf jahrzehntelanger Forschung im Bereich spekulative Ausführung und Parallelverarbeitung. Die Informatik hat seit langem erkannt, dass eine intelligente Vorhersage zukünftiger Zustände die Systemeffizienz dramatisch verbessern kann, ein Prinzip, das bei der Vorhersage von CPU-Zweigen, der spekulativen Ausführung und zahlreichen anderen Optimierungstechniken ausgenutzt wird. Die Anwendung dieser Konzepte durch Google auf die KI-Token-Generierung zeigt, wie etablierte Computerarchitekturprinzipien bei der Anwendung auf moderne maschinelle Lernsysteme neue Fähigkeiten erschließen können. Die MTP-Technologie wendet dieses bewährte Spielbuch im Wesentlichen auf die sequentielle Natur der Sprachmodellinferenz an und wandelt einen zuvor streng sequentiellen Prozess in einen Prozess mit erheblichen Parallelisierungsmöglichkeiten um.
Leistungsbenchmarking der Multi-Token Prediction-Entwickler wird in den kommenden Monaten zweifellos ein wichtiger Schwerpunkt für die Entwicklergemeinschaft sein. Erste Hinweise deuten darauf hin, dass die Geschwindigkeitsverbesserung um das Dreifache realistische Leistungssteigerungen über eine Vielzahl von Hardwarekonfigurationen und Anwendungsfällen hinweg darstellt. Die tatsächlichen Ergebnisse können jedoch je nach Modellgröße, Quantisierungsniveau und Zielhardwareplattform variieren. Entwickler, die an der Evaluierung der MTP-Technologie interessiert sind, können bereits mit den von Google veröffentlichten experimentellen Modellen experimentieren und so wertvolles Feedback liefern, das wahrscheinlich in zukünftige Iterationen und Optimierungen einfließen wird. Die von dieser Early-Adopter-Community generierten realen Leistungsdaten werden sich als entscheidend erweisen, um zu verstehen, wo die MTP-Technologie die größten Vorteile bietet und wo sich zusätzliche Optimierungsarbeiten als lohnenswert erweisen könnten.
Mit Blick auf die Zukunft wird Edge AI durch die Konvergenz von verbesserter KI-Modelleffizienz, freizügigerer Lizenzierung und bahnbrechenden Inferenzoptimierungstechniken zu einer zunehmend überzeugenden Alternative zu Cloud-zentrierten KI-Architekturen. Da sich Unternehmen weltweit mit Datenschutzbestimmungen, Cloud-Service-Kosten und Latenzanforderungen auseinandersetzen, werden Technologien wie Gemma 4 mit Multi-Token Prediction zu strategisch wichtigen Werkzeugen für ihre Technologie-Roadmaps. Die anhaltenden Investitionen von Google in Open-Source-KI-Modelle und Leistungsverbesserungen lassen darauf schließen, dass das Unternehmen sowohl den technischen Wert als auch die Marktnachfrage nach lokal einsetzbaren KI-Systemen erkennt. Während das Ökosystem reifer wird und Entwickler innovative Anwendungen entwickeln, die diese Fähigkeiten nutzen, werden die Auswirkungen dieser technologischen Fortschritte wahrscheinlich weit über die unmittelbare Entwicklergemeinschaft hinausgehen und die Art und Weise verändern, wie KI in unzähligen Organisationen und Anwendungsfällen eingesetzt wird.
Quelle: Ars Technica


