La IA Gemma 4 de Google obtiene un aumento de velocidad 3 veces mayor

Los modelos de IA Gemma 4 de Google ahora cuentan con tecnología de predicción multitoken, que ofrece un rendimiento 3 veces más rápido. Descubra cómo la decodificación especulativa mejora el procesamiento local de la IA.
modelos de IA Gemma 4 de Google acaban de recibir una importante mejora de rendimiento que podría transformar la forma en que los desarrolladores abordan la implementación de IA de vanguardia. El gigante de las búsquedas presentó sus modelos de inteligencia artificial de código abierto Gemma 4 a principios de esta primavera con capacidades impresionantes diseñadas para la ejecución local, y ahora la compañía está yendo aún más lejos con la innovadora tecnología de Predicción Multi-Token (MTP). Este avance innovador promete revolucionar la velocidad de inferencia, ofreciendo potencialmente una generación de tokens hasta 3 veces más rápida en comparación con los enfoques convencionales. La introducción de redactores de MTP representa un gran avance para hacer que la IA potente sea accesible y eficiente para escenarios de computación de vanguardia.
En el centro de esta mejora del rendimiento se encuentra una técnica sofisticada llamada decodificación especulativa, que cambia fundamentalmente la forma en que los modelos de IA generan texto y otros resultados. En lugar de predecir un token a la vez de manera secuencial, el sistema de predicción de múltiples tokens aprovecha algoritmos avanzados para pronosticar de manera inteligente múltiples tokens futuros simultáneamente. Este enfoque permite al sistema "mirar hacia el futuro" y hacer conjeturas fundamentadas sobre lo que sigue en el proceso de generación, lo que reduce drásticamente la sobrecarga computacional y la latencia asociadas con la generación tradicional token por token. El equipo de investigación de Google ha diseñado estos modelos experimentales para que funcionen perfectamente con la arquitectura de Gemma, lo que permite a los desarrolladores aprovechar esta ventaja de velocidad sin necesidad de modificaciones significativas en sus flujos de trabajo existentes.
La arquitectura de los modelos Gemma 4 se basa en la misma tecnología fundamental que impulsa el vanguardista sistema de inteligencia artificial Gemini de Google, que representa la oferta de modelo de lenguaje grande más avanzada de la compañía. Sin embargo, si bien Gemini está optimizado para funcionar en los centros de datos patentados de Google y en hardware personalizado, Gemma 4 se ha ajustado y perfeccionado específicamente para funcionar de manera eficiente en hardware local y dispositivos de borde. Esta estrategia de localización significa que los desarrolladores ya no necesitan depender de la infraestructura de la nube ni enviar datos confidenciales a servidores remotos, lo que cambia fundamentalmente el cálculo para las organizaciones preocupadas por la privacidad y aquellas con estrictos requisitos de gobernanza de datos. El enfoque de ingeniería demuestra el compromiso de Google de democratizar la tecnología avanzada de IA en diversos entornos informáticos.
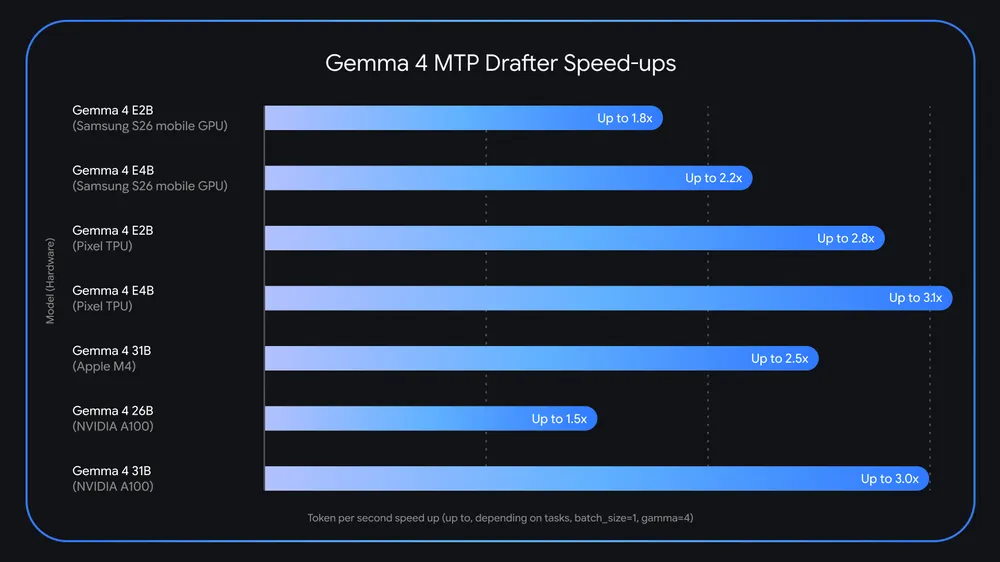
La experiencia en infraestructura de Google influye claramente en el diseño de Gemma 4, ya que la empresa tradicionalmente ha optimizado sus sistemas de inteligencia artificial para aprovechar chips TPU personalizados que operan en clústeres masivos con velocidades de interconexión y ancho de banda de memoria extraordinarios. Estos procesadores especializados, desarrollados a lo largo de años de investigación sobre aprendizaje automático de Google, brindan enormes ventajas computacionales en entornos de centros de datos donde Gemini alcanza su máximo potencial. Para Gemma, sin embargo, la filosofía de ingeniería cambia drásticamente: los modelos están diseñados para funcionar de manera eficiente en hardware estándar de consumo. Un único acelerador de IA de alto rendimiento puede ejecutar con éxito incluso los modelos Gemma 4 más grandes con total precisión, ofreciendo velocidades de inferencia respetables sin hardware especializado exótico.
Para los desarrolladores que trabajan con presupuestos de hardware más modestos, las técnicas de cuantificación ofrecen una vía adicional para implementar Gemma 4 de manera efectiva. La cuantificación reduce la precisión numérica de los pesos y activaciones del modelo, generalmente convirtiendo de punto flotante de 32 bits a formatos de menor precisión, como enteros de 8 bits o valores de 4 bits. Este enfoque de compresión no solo reduce los requisitos de memoria, sino que también acelera la computación, lo que permite que incluso las GPU de consumo manejen modelos sustanciales de IA. Combinados con la mejora de Predicción Multi-Token, los modelos Gemma 4 cuantificados podrían ofrecer características de rendimiento notables en computadoras portátiles, servidores perimetrales y otros entornos con recursos limitados. Esta accesibilidad representa un momento decisivo para la implementación local de IA, eliminando las barreras tradicionales que históricamente han limitado las capacidades avanzadas de IA a las organizaciones con buenos recursos.

Las consideraciones de privacidad han impulsado durante mucho tiempo el interés en los sistemas de IA de vanguardia, y Gemma 4 con tecnología MTP amplifica considerablemente esta propuesta de valor. Al permitir la inferencia avanzada de IA directamente en el hardware local, estos modelos eliminan la necesidad de transmitir datos confidenciales a servicios en la nube operados por Google o proveedores de la competencia. Este enfoque arquitectónico resulta particularmente valioso para las organizaciones que manejan información comercial confidencial, datos de atención médica protegidos por las regulaciones HIPAA o información personal sujeta al RGPD y marcos de privacidad similares. La capacidad de realizar tareas sofisticadas de IA sin salir del entorno informático local aborda los requisitos normativos y, al mismo tiempo, reduce la latencia y mejora la experiencia del usuario a través de tiempos de respuesta más rápidos.
La decisión de Google de volver a otorgar la licencia de Gemma 4 bajo la licencia de código abierto Apache 2.0 representa otra consideración crucial para los desarrolladores y organizaciones que evalúan la adopción. La licencia Apache 2.0 proporciona una permisividad significativamente mayor en comparación con la licencia Gemma personalizada original de Google, ofreciendo libertades más amplias para uso comercial, modificación y distribución. Este cambio alinea Gemma 4 con las mejores prácticas de la industria para la IA de código abierto y posiciona los modelos como recursos genuinamente accesibles para la comunidad de desarrolladores en general. El cambio de licencia elimina efectivamente la ambigüedad legal que anteriormente podría haber complicado implementaciones comerciales o modificaciones significativas a los modelos base. Para las empresas que evalúan su estrategia de infraestructura de IA, este panorama de licencias más permisivo mejora sustancialmente el cálculo de riesgos en torno a la adopción de Gemma.
La innovación técnica de la predicción multitoken se basa en décadas de investigación en ejecución especulativa y procesamiento paralelo. La informática ha reconocido desde hace mucho tiempo que la predicción inteligente de estados futuros puede mejorar drásticamente la eficiencia del sistema, un principio explotado en la predicción de ramas de la CPU, la ejecución especulativa y muchas otras técnicas de optimización. La aplicación de estos conceptos por parte de Google a la generación de tokens de IA demuestra cómo los principios establecidos de la arquitectura informática pueden desbloquear nuevas capacidades cuando se aplican a los sistemas modernos de aprendizaje automático. La tecnología MTP esencialmente aplica este manual probado a la naturaleza secuencial de la inferencia del modelo de lenguaje, transformando lo que antes era un proceso estrictamente secuencial en uno con importantes oportunidades de paralelización.
La evaluación comparativa del rendimiento de los redactores de Predicción de múltiples tokens sin duda se convertirá en un enfoque fundamental para la comunidad de desarrolladores en los próximos meses. Los indicios iniciales sugieren que la mejora de la velocidad 3x representa ganancias de rendimiento realistas en una variedad de configuraciones de hardware y casos de uso, aunque los resultados reales pueden variar según los tamaños de modelo específicos, los niveles de cuantificación y las plataformas de hardware de destino. Los desarrolladores interesados en evaluar la tecnología MTP ya pueden comenzar a experimentar con los modelos experimentales lanzados por Google, proporcionando comentarios valiosos que probablemente informarán futuras iteraciones y optimizaciones. Los datos de rendimiento del mundo real generados por esta comunidad de usuarios pioneros resultarán esenciales para comprender dónde la tecnología MTP ofrece los beneficios más sustanciales y dónde podría resultar útil un trabajo de optimización adicional.
De cara al futuro, la convergencia de una eficiencia del modelo de IA mejorada, licencias más permisivas y técnicas innovadoras de optimización de inferencia posicionan a la IA periférica como una alternativa cada vez más convincente a las arquitecturas de IA centradas en la nube. A medida que las organizaciones de todo el mundo se enfrentan a las regulaciones de privacidad de datos, los costos de los servicios en la nube y los requisitos de latencia, tecnologías como Gemma 4 con predicción multitoken se convierten en herramientas estratégicamente importantes para sus hojas de ruta tecnológicas. La inversión continua de Google en modelos de IA de código abierto y mejoras de rendimiento sugiere que la compañía reconoce tanto el mérito técnico como la demanda del mercado de sistemas de IA implementables localmente. A medida que el ecosistema madure y los desarrolladores creen aplicaciones innovadoras aprovechando estas capacidades, el impacto de estos avances tecnológicos probablemente se extenderá mucho más allá de la comunidad de desarrolladores inmediata para remodelar la forma en que se implementa la IA en innumerables organizaciones y casos de uso.
Fuente: Ars Technica


