L'intelligenza artificiale Gemma 4 di Google ottiene un aumento di velocità 3 volte maggiore

I modelli Gemma 4 AI di Google ora sono dotati della tecnologia Multi-Token Prediction, che offre prestazioni 3 volte più veloci. Scopri come la decodifica speculativa migliora l'elaborazione dell'intelligenza artificiale locale.
I modelli di intelligenza artificiale Gemma 4 di Google hanno appena ricevuto un significativo aggiornamento delle prestazioni che potrebbe trasformare il modo in cui gli sviluppatori affrontano l'implementazione dell'intelligenza artificiale all'avanguardia. Il colosso della ricerca ha presentato i suoi modelli di intelligenza artificiale open source Gemma 4 all'inizio di questa primavera con funzionalità impressionanti progettate per l'esecuzione locale, e ora l'azienda sta spingendo ulteriormente i limiti con la rivoluzionaria tecnologia Multi-Token Prediction (MTP). Questo progresso innovativo promette di rivoluzionare la velocità di inferenza, offrendo potenzialmente una generazione di token fino a 3 volte più veloce rispetto agli approcci convenzionali. L'introduzione dei drafter MTP rappresenta un grande passo avanti nel rendere la potente IA accessibile ed efficiente per gli scenari di edge computing.
Al centro di questo miglioramento delle prestazioni c'è una tecnica sofisticata chiamata decodifica speculativa, che cambia radicalmente il modo in cui i modelli di intelligenza artificiale generano testo e altri output. Invece di prevedere un token alla volta in modo sequenziale, il sistema di previsione multi-token sfrutta algoritmi avanzati per prevedere in modo intelligente più token futuri contemporaneamente. Questo approccio consente al sistema di "guardare avanti" e fare ipotesi plausibili su ciò che verrà dopo nel processo di generazione, riducendo drasticamente il sovraccarico computazionale e la latenza associati alla tradizionale generazione token per token. Il team di ricerca di Google ha progettato questi modelli sperimentali in modo che funzionino perfettamente con l'architettura di Gemma, consentendo agli sviluppatori di sfruttare questo vantaggio in termini di velocità senza richiedere modifiche significative ai flussi di lavoro esistenti.
L'architettura dei modelli Gemma 4 si basa sulla stessa tecnologia di base che alimenta il sistema di intelligenza artificiale Gemini all'avanguardia di Google, che rappresenta l'offerta di modello linguistico di grandi dimensioni più avanzata dell'azienda. Tuttavia, mentre Gemini è ottimizzato per il funzionamento sui data center proprietari di Google e su hardware personalizzato, Gemma 4 è stato specificatamente messo a punto e perfezionato per funzionare in modo efficiente su hardware locale e dispositivi edge. Questa strategia di localizzazione fa sì che gli sviluppatori non debbano più fare affidamento sull’infrastruttura cloud o inviare dati sensibili a server remoti, cambiando radicalmente il calcolo per le organizzazioni attente alla privacy e quelle con rigorosi requisiti di governance dei dati. L'approccio ingegneristico dimostra l'impegno di Google nella democratizzazione della tecnologia IA avanzata in diversi ambienti informatici.
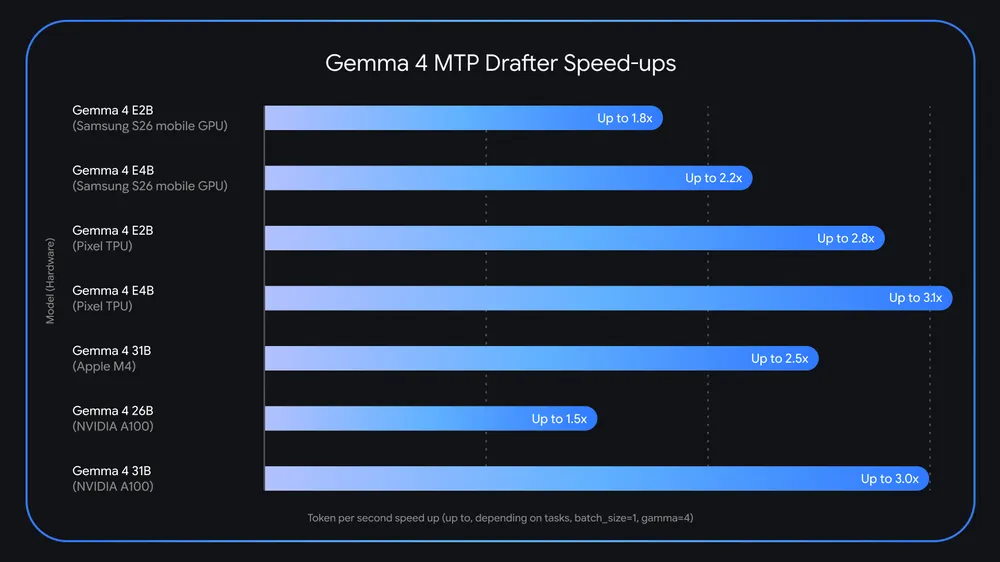
Il background dell'infrastruttura di Google influenza chiaramente il design di Gemma 4, poiché l'azienda ha tradizionalmente ottimizzato i suoi sistemi di intelligenza artificiale per sfruttare chip TPU personalizzati che operano in enormi cluster con velocità di interconnessione e larghezza di banda della memoria straordinarie. Questi processori specializzati, sviluppati nel corso di anni di ricerca sul machine learning di Google, offrono enormi vantaggi computazionali negli ambienti data center in cui Gemini raggiunge il suo pieno potenziale. Per Gemma, tuttavia, la filosofia ingegneristica cambia radicalmente: i modelli sono progettati per funzionare in modo efficiente su hardware standard di livello consumer. Un singolo acceleratore AI ad alte prestazioni può eseguire con successo anche i modelli Gemma 4 più grandi alla massima precisione, offrendo velocità di inferenza rispettabili senza hardware specializzato esotico.
Per gli sviluppatori che lavorano con budget hardware più modesti, le tecniche di quantizzazione offrono un ulteriore percorso per distribuire Gemma 4 in modo efficace. La quantizzazione riduce la precisione numerica dei pesi e delle attivazioni del modello, in genere convertendo da formati a virgola mobile a 32 bit a formati a precisione inferiore come numeri interi a 8 bit o valori a 4 bit. Questo approccio di compressione non solo riduce i requisiti di memoria, ma accelera anche il calcolo, consentendo anche alle GPU di livello consumer di gestire modelli di intelligenza artificiale sostanziali. Combinati con il miglioramento della previsione multi-token, i modelli Gemma 4 quantizzati potrebbero offrire caratteristiche prestazionali straordinarie su laptop, server edge e altri ambienti con risorse limitate. Questa accessibilità rappresenta un momento di svolta per l'implementazione locale dell'IA, rimuovendo le barriere tradizionali che storicamente hanno limitato le capacità avanzate dell'IA alle organizzazioni dotate di risorse adeguate.

Le considerazioni sulla privacy alimentano da tempo l'interesse per i sistemi di intelligenza artificiale all'avanguardia e Gemma 4 con la tecnologia MTP amplifica notevolmente questa proposta di valore. Abilitando l’inferenza avanzata dell’intelligenza artificiale direttamente sull’hardware locale, questi modelli eliminano la necessità di trasmettere dati sensibili ai servizi cloud gestiti da Google o da fornitori concorrenti. Questo approccio architetturale si rivela particolarmente prezioso per le organizzazioni che gestiscono informazioni aziendali riservate, dati sanitari protetti dalle normative HIPAA o informazioni personali soggette al GDPR e simili quadri sulla privacy. La capacità di eseguire attività di intelligenza artificiale sofisticate senza lasciare l'ambiente informatico locale soddisfa i requisiti normativi riducendo al tempo stesso la latenza e migliorando l'esperienza utente attraverso tempi di risposta più rapidi.
La decisione di Google di concedere nuovamente in licenza Gemma 4 con la licenza open source Apache 2.0 rappresenta un'altra considerazione cruciale per gli sviluppatori e le organizzazioni che valutano l'adozione. La licenza Apache 2.0 fornisce una permissività significativamente maggiore rispetto alla licenza Gemma personalizzata originale di Google, offrendo libertà più ampie per uso commerciale, modifica e distribuzione. Questo cambiamento allinea Gemma 4 con le migliori pratiche del settore per l’intelligenza artificiale open source e posiziona i modelli come risorse realmente accessibili per la più ampia comunità di sviluppatori. La modifica della licenza rimuove efficacemente l’ambiguità legale che in precedenza avrebbe potuto complicare le implementazioni commerciali o apportare modifiche significative ai modelli di base. Per le aziende che stanno valutando la propria strategia per l'infrastruttura IA, questo panorama di licenze più permissivo migliora sostanzialmente il calcolo del rischio legato all'adozione di Gemma.
L'innovazione tecnica di Multi-Token Prediction si basa su decenni di ricerca nell'esecuzione speculativa e nell'elaborazione parallela. L’informatica ha da tempo riconosciuto che la previsione intelligente degli stati futuri può migliorare notevolmente l’efficienza del sistema, un principio sfruttato nella previsione dei rami della CPU, nell’esecuzione speculativa e in numerose altre tecniche di ottimizzazione. L'applicazione di questi concetti da parte di Google alla generazione di token AI dimostra come i principi consolidati dell'architettura informatica possano sbloccare nuove funzionalità se applicati ai moderni sistemi di apprendimento automatico. La tecnologia MTP applica essenzialmente questo metodo collaudato alla natura sequenziale dell'inferenza del modello linguistico, trasformando quello che in precedenza era un processo strettamente sequenziale in un processo con significative opportunità di parallelizzazione.
Il benchmarking delle prestazioni dei redattori di Multi-Token Prediction diventerà senza dubbio un punto focale per la comunità degli sviluppatori nei prossimi mesi. Le indicazioni iniziali suggeriscono che il miglioramento della velocità di 3 volte rappresenta guadagni prestazionali realistici in una varietà di configurazioni hardware e casi d'uso, sebbene i risultati effettivi possano variare a seconda delle dimensioni specifiche del modello, dei livelli di quantizzazione e delle piattaforme hardware di destinazione. Gli sviluppatori interessati a valutare la tecnologia MTP possono già iniziare a sperimentare con i modelli sperimentali rilasciati da Google, fornendo feedback preziosi che probabilmente informeranno le future iterazioni e ottimizzazioni. I dati sulle prestazioni nel mondo reale generati da questa comunità di early adopter si riveleranno essenziali per comprendere dove la tecnologia MTP offre i vantaggi più sostanziali e dove un ulteriore lavoro di ottimizzazione potrebbe rivelarsi utile.
Guardando al futuro, la convergenza tra una migliore efficienza del modello di intelligenza artificiale, licenze più permissive e tecniche di ottimizzazione dell'inferenza rivoluzionarie posiziona l'intelligenza artificiale all'avanguardia come un'alternativa sempre più convincente alle architetture di intelligenza artificiale incentrate sul cloud. Mentre le organizzazioni di tutto il mondo sono alle prese con le normative sulla privacy dei dati, i costi dei servizi cloud e i requisiti di latenza, tecnologie come Gemma 4 con Multi-Token Prediction diventano strumenti strategicamente importanti per le loro roadmap tecnologiche. I continui investimenti di Google in modelli di intelligenza artificiale open source e miglioramenti delle prestazioni suggeriscono che l’azienda riconosce sia il merito tecnico che la domanda del mercato per sistemi di intelligenza artificiale distribuibili localmente. Man mano che l'ecosistema matura e gli sviluppatori creano applicazioni innovative sfruttando queste capacità, l'impatto di questi progressi tecnologici probabilmente si estenderà ben oltre la comunità immediata degli sviluppatori per rimodellare il modo in cui l'intelligenza artificiale viene distribuita in innumerevoli organizzazioni e casi d'uso.
Fonte: Ars Technica


