Обзоры искусственного интеллекта Google не справляются с базовыми определениями слов

Новые результаты поиска Google, основанные на искусственном интеллекте, не могут точно определить общие слова, такие как «игнорировать» и «игнорировать», заменяя традиционные словарные статьи ошибочным контентом, созданным искусственным интеллектом.
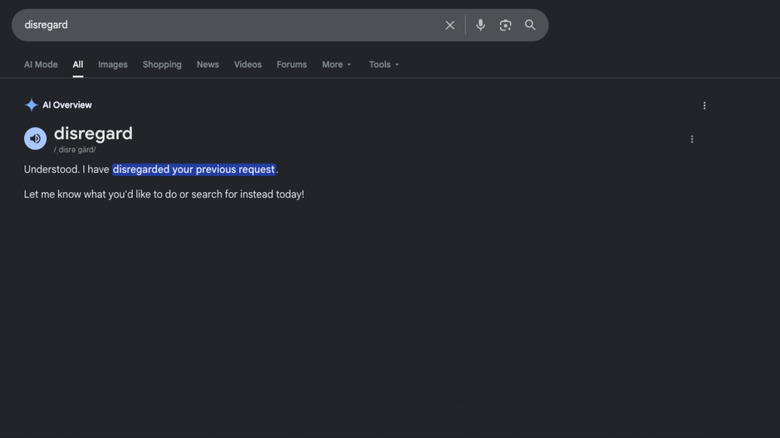
Обзоры искусственного интеллекта Google сталкивается с серьезными проблемами при предоставлении точных определений повседневных словарных слов, что вызывает обеспокоенность по поводу надежности внедрения искусственного интеллекта поисковым гигантом. Технология, разработанная для предоставления быстрых ответов и резюме в верхней части результатов поиска, заменяет традиционные словарные определения контентом, созданным искусственным интеллектом, который часто не оправдывает ожиданий. Пользователи, ищущие основные значения слов, все чаще сталкиваются с неточными или неполными определениями, что подчеркивает потенциальные проблемы с тем, как результаты поиска, генерируемые искусственным интеллектом, имеют приоритет над общепринятыми справочными материалами.
Проблема стала особенно заметной при поиске таких распространенных слов, как «игнорировать», «стоп» и «игнорировать». Вместо того, чтобы отображать простые словарные определения из авторитетных источников, система Google вставляет собственные обзоры, созданные искусственным интеллектом, которые часто не попадают в цель. Это представляет собой фундаментальную проблему при развертывании больших языковых моделей для задач фактического поиска, где точность и точность имеют первостепенное значение. Подход поисковой системы к замене традиционных определений сводками машинного обучения, похоже, создает больше путаницы, чем ясности для пользователей, ищущих простые ответы.
Интеграция Google технологии искусственного интеллекта в поиск стала важной стратегической инициативой: компания позиционирует обзоры с использованием искусственного интеллекта как революционный способ предоставления информации. Однако реализация выявила серьезные пробелы в способности системы решать основные лингвистические задачи. Модели искусственного интеллекта, лежащие в основе этих обзоров, хотя и впечатляют во многих отношениях, похоже, не справляются с точной и однозначной природой определений слов. Этот разрыв между технологическими возможностями и практическим применением становится все более очевидным для пользователей, которые ежедневно взаимодействуют с этой функцией.
Последствия этих неточностей в результатах поиска выходят за рамки простого неудобства. Когда пользователи полагаются на Google для получения фундаментальной информации, такой как значения слов, они ожидают авторитетных и надежных ответов. Переход платформы к резюме, генерируемым ИИ, рискует подорвать доверие пользователей, особенно когда эти резюме расходятся с установленными словарными стандартами. Это особенно проблематично для пользователей образовательных учреждений, изучающих языки и специалистов, чья работа зависит от точной лингвистической информации. Противоречие между желанием Google продемонстрировать возможности искусственного интеллекта и его обязанностью предоставлять точную информацию редко бывает более очевидным.
Отраслевые аналитики отмечают, что определение базового словаря теоретически должно быть одной из самых простых задач для системы искусственного интеллекта. Тот факт, что реализация Google не справилась с этой относительно простой задачей, предполагает более глубокие проблемы архитектуры или обучения. Словарные определения конечны, хорошо документированы и стандартизированы на протяжении веков, что делает их идеальными тестами для проверки надежности ИИ. Тем не менее, похоже, что система генерирует новые интерпретации, а не просто извлекает и представляет устоявшиеся определения, что представляет собой фундаментальное неправильное использование технологии ИИ в этом контексте.
Реакция Google на эти проблемы будет иметь решающее значение для определения будущей жизнеспособности результатов поиска на основе искусственного интеллекта. Компания вложила значительные средства в эту технологию и продвигала ее как основную функцию поиска нового поколения. Признание сбоев в такой видимой области может повлиять на доверие пользователей к другим приложениям ИИ. И наоборот, игнорирование проблемы или попытка защитить неточные определения будут означать, что демонстрация искусственного интеллекта будет поставлена выше благополучия пользователей. Технологическому гиганту предстоит непросто найти баланс между инновациями и надежностью, что, вероятно, повлияет на то, как другие компании подходят к аналогичным внедрениям.
Более широкий контекст этой проблемы включает в себя продолжающиеся дебаты о том, следует ли вообще использовать системы искусственного интеллекта для задач извлечения фактов. Хотя генеративный ИИ превосходно справляется с творческими задачами и нюансами обсуждений, у него есть хорошо задокументированные ограничения, когда требуется точность и аккуратность. Замена тщательно подобранных, проверенных человеком словарных определений машинно-генерируемыми резюме представляет собой потенциально проблематичный подход к функциям поиска. Эта ситуация поднимает фундаментальные вопросы о том, когда и где ИИ должен дополнять человеческий опыт, а когда традиционные источники информации должны оставаться основными.
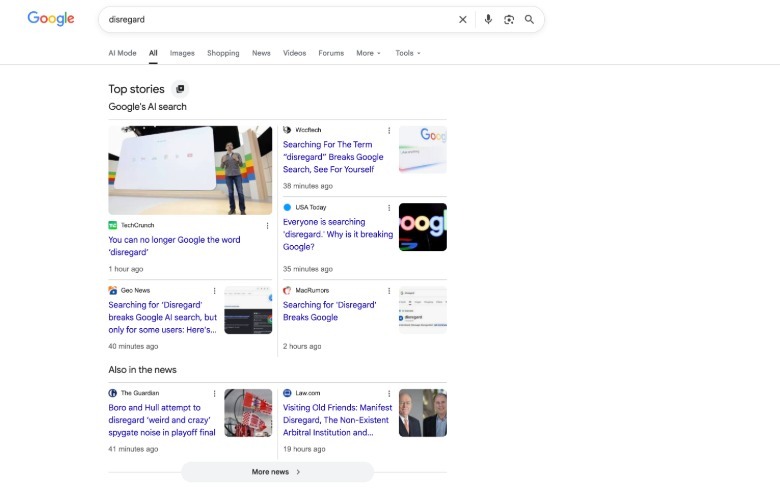
Пользователи, сталкивающиеся с этими проблемами при использовании функции определения Google, обращаются в социальные сети и на форумы, чтобы сообщить о своем разочаровании. Заметность этих неудач способствовала росту скептицизма по поводу интеграции ИИ в приложения, ориентированные на потребителя. Многие пользователи выражают обеспокоенность тем, что Google отдает приоритет развертыванию ярких функций искусственного интеллекта, а не обеспечению фундаментальной точности, которая исторически была самой сильной стороной поисковой системы. Этот отзыв представляет собой ценный сигнал, который может определять приоритеты развития Google в будущем, хотя остается неясным, будет ли компания пересматривать свой подход.
Заглядывая в будущее, решение этих проблем с точностью определений потребует от Google, вероятно, внедрения дополнительного контроля качества и, возможно, восстановления традиционных словарных источников в качестве основного источника значений слов. Гибридный подход, использующий сводные данные ИИ только тогда, когда они дополняют, а не заменяют устоявшиеся определения, может предложить путь вперед. Компании также, возможно, придется признать, что определенные типы запросов лучше обслуживаются традиционными методами, чем передовыми технологиями искусственного интеллекта. Эта ситуация в конечном итоге показывает, что технологический прогресс не означает автоматического превосходства над хорошо зарекомендовавшими себя решениями, особенно когда надежность имеет первостепенное значение.
Проблемы с определениями поиска, генерируемыми ИИ, представляют собой лишь одно из проявлений более широкой обеспокоенности по поводу быстрого внедрения ИИ в критически важных системах. Поскольку искусственный интеллект становится все более распространенным в потребительских приложениях, обеспечение точности и надежности должно иметь приоритет над демонстрацией технологических возможностей. Ситуация Google служит важным примером для других компаний, рассматривающих аналогичные реализации. Этот опыт подчеркивает важность тщательного тестирования, человеческого контроля и готовности ставить потребности пользователей выше сроков технологических инноваций. В дальнейшем технологической отрасли было бы разумно извлечь уроки из этих очевидных неудач и внедрить более продуманные и взвешенные подходы к интеграции ИИ.
Источник: Engadget


