Скорость искусственного интеллекта Gemma 4 от Google увеличена в 3 раза

Модели Google Gemma 4 AI теперь оснащены технологией Multi-Token Prediction, обеспечивающей в 3 раза более высокую производительность. Узнайте, как спекулятивное декодирование улучшает локальную обработку данных ИИ.
Модели искусственного интеллекта Gemma 4 от Google только что получили значительное повышение производительности, которое может изменить подход разработчиков к развертыванию периферийного искусственного интеллекта. Ранее этой весной поисковый гигант представил свои модели искусственного интеллекта Gemma 4 с открытым исходным кодом, обладающие впечатляющими возможностями, предназначенными для локального исполнения, а теперь компания расширяет границы возможного с помощью новаторской технологии Multi-Token Prediction (MTP). Это инновационное достижение обещает революционизировать скорость вывода, потенциально обеспечивая генерацию токенов в 3 раза быстрее по сравнению с традиционными подходами. Появление разработчиков MTP представляет собой большой шаг вперед в обеспечении доступности и эффективности мощного искусственного интеллекта для сценариев периферийных вычислений.
В основе этого повышения производительности лежит сложная технология под названием спекулятивное декодирование, которая фундаментально меняет то, как модели ИИ генерируют текст и другие выходные данные. Вместо последовательного прогнозирования одного токена за раз, система прогнозирования нескольких токенов использует передовые алгоритмы для интеллектуального прогнозирования нескольких будущих токенов одновременно. Этот подход позволяет системе «заглядывать вперед» и делать обоснованные предположения о том, что будет дальше в процессе генерации, значительно сокращая вычислительные затраты и задержки, связанные с традиционной генерацией токенов. Исследовательская группа Google разработала эти экспериментальные модели для безупречной работы с архитектурой Gemma, что позволяет разработчикам использовать это преимущество в скорости, не требуя значительных изменений в существующих рабочих процессах.
Архитектура моделей Gemma 4 построена на той же основополагающей технологии, которая лежит в основе новейшей системы искусственного интеллекта Gemini от Google, которая представляет собой самое передовое предложение компании большая языковая модель. Однако, хотя Gemini оптимизирован для работы в собственных центрах обработки данных Google и на специальном оборудовании, Gemma 4 была специально настроена и усовершенствована для эффективной работы на локальном оборудовании и периферийных устройствах. Эта стратегия локализации означает, что разработчикам больше не нужно полагаться на облачную инфраструктуру или отправлять конфиденциальные данные на удаленные серверы, что фундаментально меняет расчеты для организаций, заботящихся о конфиденциальности, и тех, у которых есть строгие требования к управлению данными. Инженерный подход демонстрирует стремление Google демократизировать передовые технологии искусственного интеллекта в различных вычислительных средах.
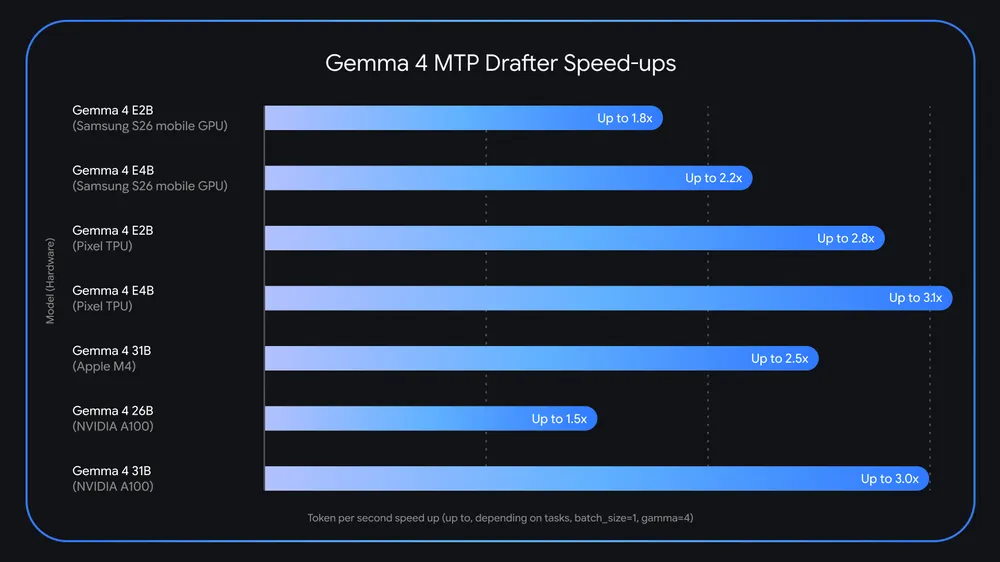
На разработку Gemma 4 явно влияет инфраструктурный опыт Google, поскольку компания традиционно оптимизировала свои системы искусственного интеллекта для использования специальных чипов TPU, которые работают в массивных кластерах с необычайной скоростью соединения и пропускной способностью памяти. Эти специализированные процессоры, разработанные в результате многолетних исследований Google в области машинного обучения, обеспечивают огромные вычислительные преимущества в средах центров обработки данных, где Gemini полностью раскрывает свой потенциал. Однако для Gemma инженерная философия кардинально изменилась: модели созданы для эффективной работы на стандартном оборудовании потребительского уровня. Один высокопроизводительный ИИ-ускоритель может успешно запускать даже самые крупные модели Gemma 4 с полной точностью, обеспечивая приличную скорость вывода без экзотического специализированного оборудования.
Для разработчиков, работающих с более скромными бюджетами на оборудование, методы квантования предлагают дополнительный путь к эффективному развертыванию Gemma 4. Квантование снижает числовую точность весов и активаций модели, обычно преобразуя 32-битные форматы с плавающей запятой в форматы с более низкой точностью, такие как 8-битные целые числа или 4-битные значения. Такой подход к сжатию не только снижает требования к памяти, но и ускоряет вычисления, позволяя даже графическим процессорам потребительского уровня обрабатывать существенные модели искусственного интеллекта. В сочетании с усовершенствованием прогнозирования нескольких токенов квантованные модели Gemma 4 могут обеспечить замечательные характеристики производительности на ноутбуках, пограничных серверах и в других средах с ограниченными ресурсами. Эта доступность представляет собой переломный момент для локального развертывания ИИ, устраняя традиционные барьеры, которые исторически ограничивали передовые возможности ИИ для организаций с хорошими ресурсами.

Соображения конфиденциальности уже давно стимулируют интерес к периферийным системам искусственного интеллекта, и Gemma 4 с технологией MTP значительно усиливает это ценное предложение. Благодаря возможности расширенного вывода ИИ непосредственно на локальном оборудовании эти модели устраняют необходимость передавать конфиденциальные данные в облачные сервисы, управляемые Google или конкурирующими поставщиками. Этот архитектурный подход оказывается особенно ценным для организаций, работающих с конфиденциальной деловой информацией, медицинскими данными, защищенными правилами HIPAA, или личной информацией, подпадающей под действие GDPR и аналогичных структур конфиденциальности. Возможность выполнять сложные задачи искусственного интеллекта, не покидая локальную вычислительную среду, соответствует нормативным требованиям, а также снижает задержку и улучшает взаимодействие с пользователем за счет более быстрого отклика.
Решение Google повторно лицензировать Gemma 4 по лицензии с открытым исходным кодом Apache 2.0 представляет собой еще одно важное соображение для разработчиков и организаций, оценивающих внедрение. Лицензия Apache 2.0 обеспечивает значительно большую свободу действий по сравнению с исходной пользовательской лицензией Gemma от Google, предлагая более широкие свободы для коммерческого использования, модификации и распространения. Этот сдвиг приводит Gemma 4 в соответствие с лучшими отраслевыми практиками в области искусственного интеллекта с открытым исходным кодом и позиционирует модели как действительно доступные ресурсы для более широкого сообщества разработчиков. Изменение лицензирования эффективно устраняет юридическую двусмысленность, которая ранее могла усложнить коммерческое внедрение или внести значительные изменения в базовые модели. Для предприятий, оценивающих свою стратегию инфраструктуры искусственного интеллекта, эта более либеральная среда лицензирования существенно улучшает расчет рисков, связанных с внедрением Gemma.
Технические инновации Multi-Token Prediction основаны на десятилетиях исследований в области спекулятивного исполнения и параллельной обработки. Информатика уже давно признала, что интеллектуальное предсказание будущих состояний может значительно повысить эффективность системы. Этот принцип используется в прогнозировании ветвей ЦП, спекулятивном выполнении и многих других методах оптимизации. Применение Google этих концепций для генерации токенов искусственного интеллекта демонстрирует, как устоявшиеся принципы компьютерной архитектуры могут открыть новые возможности при применении к современным системам машинного обучения. Технология MTP по существу применяет этот проверенный сценарий к последовательному характеру вывода языковой модели, превращая то, что раньше было строго последовательным процессом, в процесс со значительными возможностями распараллеливания.
Сравнительный анализ производительности разработчиков Multi-Token Prediction, несомненно, станет критически важным направлением для сообщества разработчиков в ближайшие месяцы. Первоначальные данные свидетельствуют о том, что трехкратное повышение скорости представляет собой реалистичный прирост производительности в различных конфигурациях оборудования и вариантах использования, хотя фактические результаты могут варьироваться в зависимости от конкретных размеров модели, уровней квантования и целевых аппаратных платформ. Разработчики, заинтересованные в оценке технологии MTP, уже могут начать экспериментировать с экспериментальными моделями, выпущенными Google, предоставляя ценную обратную связь, которая, вероятно, послужит основой для будущих итераций и оптимизаций. Данные о реальной производительности, собранные этим сообществом первых пользователей, окажутся важными для понимания того, где технология MTP обеспечивает наиболее существенные преимущества и где может оказаться целесообразным дополнительная работа по оптимизации.
В перспективе конвергенция улучшенной эффективности модели ИИ, более либерального лицензирования и революционных методов оптимизации вывода делает ИИ все более привлекательной альтернативой облачным архитектурам ИИ. Поскольку организации по всему миру сталкиваются с проблемами конфиденциальности данных, затратами на облачные услуги и требованиями к задержке, такие технологии, как Gemma 4 с прогнозированием нескольких токенов, становятся стратегически важными инструментами для их технологических планов. Продолжающиеся инвестиции Google в модели искусственного интеллекта с открытым исходным кодом и повышение производительности позволяют предположить, что компания признает как технические достоинства, так и рыночный спрос на локально развертываемые системы искусственного интеллекта. По мере развития экосистемы и разработчиков инновационных приложений, использующих эти возможности, влияние этих технологических достижений, вероятно, выйдет далеко за пределы непосредственного сообщества разработчиков и изменит способы внедрения ИИ в бесчисленных организациях и сценариях использования.
Источник: Ars Technica


