ШІ Gemma 4 від Google отримує 3-кратне збільшення швидкості

Моделі Google Gemma 4 AI тепер оснащені технологією Multi-Token Prediction, яка забезпечує втричі більшу продуктивність. Дізнайтеся, як спекулятивне декодування покращує локальну обробку ШІ.
Моделі Google Gemma 4 AI щойно отримали значне підвищення продуктивності, яке може змінити підхід розробників до розгортання граничного штучного інтелекту. Пошуковий гігант представив свої моделі ШІ з відкритим вихідним кодом Gemma 4 на початку цієї весни з вражаючими можливостями, розробленими для локального виконання, а тепер компанія розширює межі ще далі за допомогою новаторської технології Multi-Token Prediction (MTP). Цей інноваційний прогрес обіцяє революціонізувати швидкість виведення, потенційно забезпечуючи до 3 разів швидшу генерацію токенів порівняно зі звичайними підходами. Запровадження MTP drafters є великим кроком уперед у тому, щоб зробити потужний штучний інтелект доступним та ефективним для сценаріїв периферійних обчислень.
В основі цього підвищення продуктивності лежить складна техніка під назвою спекулятивне декодування, яка докорінно змінює те, як моделі ШІ генерують текст та інші результати. Замість того, щоб послідовно прогнозувати один токен за раз, система Multi-Token Prediction використовує розширені алгоритми для інтелектуального прогнозування кількох майбутніх токенів одночасно. Цей підхід дозволяє системі «заглядати вперед» і робити обґрунтовані припущення про те, що буде далі в процесі генерації, різко зменшуючи обчислювальні накладні витрати та затримку, пов’язану з традиційною генерацією маркерів за маркерами. Дослідницька група Google розробила ці експериментальні моделі для безперебійної роботи з архітектурою Gemma, дозволяючи розробникам скористатися цією перевагою швидкості, не вимагаючи істотних змін у своїх існуючих робочих процесах.
Архітектура моделей Gemma 4 побудована на тій самій базовій технології, що й у передовій системі Google Gemini AI, яка представляє найдосконалішу пропозицію великої мови компанії. Однак у той час як Gemini оптимізовано для роботи на власних центрах обробки даних Google і спеціальному обладнанні, Gemma 4 було спеціально налаштовано та доопрацьовано для ефективної роботи на локальному обладнанні та периферійних пристроях. Ця стратегія локалізації означає, що розробникам більше не потрібно покладатися на хмарну інфраструктуру або надсилати конфіденційні дані на віддалені сервери, докорінно змінюючи обчислення для організацій, які піклуються про конфіденційність, і тих, хто має суворі вимоги до керування даними. Інженерний підхід демонструє відданість Google демократизації передової технології ШІ в різноманітних обчислювальних середовищах.
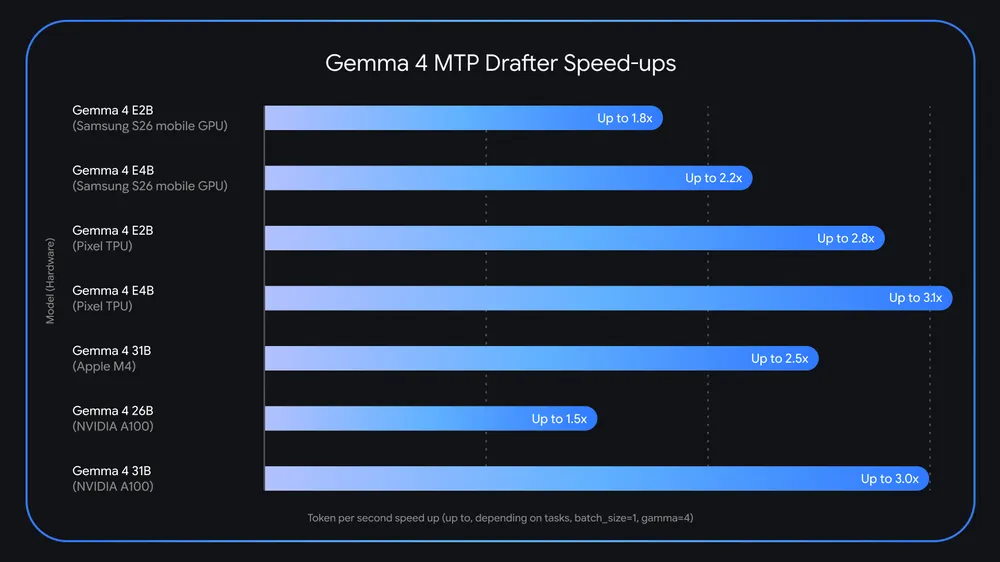
Інфраструктура Google явно впливає на дизайн Gemma 4, оскільки компанія традиційно оптимізувала свої системи штучного інтелекту для використання спеціальних чіпів TPU, які працюють у масивних кластерах із надзвичайною швидкістю з’єднання та пропускною здатністю пам’яті. Ці спеціалізовані процесори, розроблені протягом багатьох років досліджень машинного навчання Google, забезпечують величезні обчислювальні переваги в середовищах центрів обробки даних, де Gemini повністю реалізує свій потенціал. Однак для Gemma інженерна філософія кардинально змінюється — моделі створені для ефективної роботи на стандартному обладнанні споживчого рівня. Один високопродуктивний прискорювач штучного інтелекту може успішно запускати навіть найбільші моделі Gemma 4 із повною точністю, забезпечуючи поважну швидкість висновку без екзотичного спеціалізованого обладнання.
Для розробників, які мають скромні бюджети на обладнання, техніки квантування пропонують додатковий шлях до ефективного розгортання Gemma 4. Квантування знижує чисельну точність вагових коефіцієнтів і активацій моделі, зазвичай перетворюючи 32-розрядні числа з плаваючою комою у формати з нижчою точністю, такі як 8-розрядні цілі чи 4-розрядні значення. Такий підхід до стиснення не тільки зменшує вимоги до пам’яті, але й прискорює обчислення, дозволяючи навіть споживчим графічним процесорам обробляти значні моделі ШІ. У поєднанні з удосконаленням Multi-Token Prediction квантовані моделі Gemma 4 можуть забезпечити чудові характеристики продуктивності на ноутбуках, периферійних серверах та інших середовищах з обмеженими ресурсами. Ця доступність є переломним моментом для локального розгортання штучного інтелекту, усуваючи традиційні бар’єри, які історично обмежували розширені можливості штучного інтелекту організаціями з хорошими ресурсами.

Міркування конфіденційності вже давно викликають інтерес до периферійних систем штучного інтелекту, і Gemma 4 із технологією MTP значно розширює цю цінність. Завдяки розширеному висновку ШІ безпосередньо на локальному апаратному забезпеченні ці моделі усувають необхідність передавати конфіденційні дані до хмарних служб Google або конкуруючих постачальників. Цей архітектурний підхід виявляється особливо цінним для організацій, які обробляють конфіденційну ділову інформацію, дані про охорону здоров’я, захищені нормами HIPAA, або особисту інформацію, яка підпадає під дію GDPR та подібних систем конфіденційності. Можливість виконувати складні завдання штучного інтелекту, не виходячи з локального обчислювального середовища, відповідає нормативним вимогам, а також зменшує затримку та покращує взаємодію з користувачем завдяки швидшому часу відповіді.
Рішення Google переліцензувати Gemma 4 за ліцензією з відкритим вихідним кодом Apache 2.0 є ще одним важливим моментом для розробників і організацій, які оцінюють впровадження. Ліцензія Apache 2.0 забезпечує значно більший дозвіл порівняно з оригінальною користувальницькою ліцензією Gemma від Google, пропонуючи ширші свободи для комерційного використання, модифікації та розповсюдження. Ця зміна узгоджує Gemma 4 з найкращими галузевими практиками штучного інтелекту з відкритим кодом і позиціонує моделі як справді доступні ресурси для ширшої спільноти розробників. Зміна ліцензування фактично усуває юридичну двозначність, яка раніше могла ускладнювати комерційне розгортання або значні модифікації базових моделей. Для підприємств, які оцінюють свою стратегію інфраструктури штучного інтелекту, цей більш дозвільний ландшафт ліцензування суттєво покращує обчислення ризиків щодо впровадження Gemma.
Технічна інновація Multi-Token Prediction базується на десятиліттях досліджень спекулятивного виконання та паралельної обробки. Інформатика давно визнала, що інтелектуальне передбачення майбутніх станів може значно підвищити ефективність системи, принцип, який використовується в передбаченні розгалужень ЦП, спекулятивному виконанні та багатьох інших методах оптимізації. Застосування Google цих концепцій до генерації маркерів штучного інтелекту демонструє, як усталені принципи комп’ютерної архітектури можуть відкрити нові можливості при застосуванні до сучасних систем машинного навчання. Технологія MTP по суті застосовує цей перевірений посібник до послідовного характеру виведення мовної моделі, перетворюючи те, що раніше було суворо послідовним процесом, у процес із значними можливостями розпаралелювання.
Порівняльний аналіз продуктивності розробників Multi-Token Prediction, безсумнівно, стане критично важливим для спільноти розробників у найближчі місяці. Початкові ознаки свідчать про те, що підвищення швидкості в 3 рази означає реалістичний приріст продуктивності в різноманітних апаратних конфігураціях і варіантах використання, хоча фактичні результати можуть відрізнятися залежно від конкретних розмірів моделі, рівнів квантування та цільових апаратних платформ. Розробники, зацікавлені в оцінці технології MTP, уже можуть почати експериментувати з експериментальними моделями, опублікованими Google, надаючи цінні відгуки, які, ймовірно, будуть корисними для майбутніх ітерацій та оптимізацій. Реальні дані про продуктивність, отримані цією спільнотою перших користувачів, виявляться важливими для розуміння того, де технологія MTP забезпечує найбільші переваги, а де додаткова робота з оптимізації може виявитися корисною.
Заглядаючи вперед, конвергенція покращеної ефективності моделі штучного інтелекту, більш дозволеного ліцензування та новаторських методів оптимізації логічного висновку позиціонує граничний штучний інтелект як дедалі привабливішу альтернативу архітектурам ШІ, орієнтованим на хмару. Оскільки організації в усьому світі стикаються з правилами конфіденційності даних, витратами на хмарні послуги та вимогами до затримки, такі технології, як Gemma 4 із Multi-Token Prediction, стають стратегічно важливими інструментами для їхніх технологічних дорожніх карт. Постійні інвестиції Google у моделі штучного інтелекту з відкритим кодом і покращення продуктивності свідчать про те, що компанія визнає як технічні переваги, так і ринковий попит на локальні системи штучного інтелекту. Оскільки екосистема розвивається та розробники створюють інноваційні програми, використовуючи ці можливості, вплив цих технологічних досягнень, ймовірно, поширюватиметься далеко за межі безпосередньої спільноти розробників, щоб змінити спосіб розгортання ШІ в незліченних організаціях і сценаріях використання.
Джерело: Ars Technica


