Google 的 Gemma 4 AI 速度提升 3 倍

Google 的 Gemma 4 AI 模型现在采用多令牌预测技术,性能提高了 3 倍。了解推测解码如何增强本地 AI 处理。
Google 的 Gemma 4 AI 模型刚刚获得了重大性能升级,这可能会改变开发者边缘 AI 部署的方式。这家搜索巨头在今年春天早些时候推出了 Gemma 4 开源人工智能模型,具有专为本地执行而设计的令人印象深刻的功能,现在该公司正在利用突破性的多令牌预测 (MTP) 技术进一步突破极限。这一创新进步有望彻底改变推理速度,与传统方法相比,可能将令牌生成速度提高 3 倍。 MTP 绘图器的引入代表着在边缘计算场景中让强大的 AI 变得易于使用和高效方面的重大飞跃。
这种性能改进的核心在于一种称为推测解码的复杂技术,它从根本上改变了人工智能模型生成文本和其他输出的方式。多令牌预测系统不是以顺序方式一次预测一个令牌,而是利用先进的算法同时智能地预测多个未来令牌。这种方法允许系统“展望未来”,并对生成过程中接下来发生的事情做出有根据的猜测,从而大大减少与传统的逐个令牌生成相关的计算开销和延迟。 Google 的研究团队设计了这些实验模型,使其能够与 Gemma 的架构无缝协作,使开发人员能够利用这种速度优势,而无需对其现有工作流程进行重大修改。
Gemma 4 模型架构建立在与 Google 尖端 Gemini AI 系统相同的基础技术之上,该系统代表了该公司最先进的大语言模型产品。然而,虽然 Gemini 针对在 Google 专有数据中心和定制硬件上的运行进行了优化,但 Gemma 4 进行了专门调整和改进,以便在本地硬件和边缘设备上高效运行。这种本地化策略意味着开发人员不再需要依赖云基础设施或将敏感数据发送到远程服务器,从根本上改变了注重隐私的组织和具有严格数据治理要求的组织的计算方式。该工程方法体现了 Google 致力于在不同的计算环境中实现先进人工智能技术的民主化。
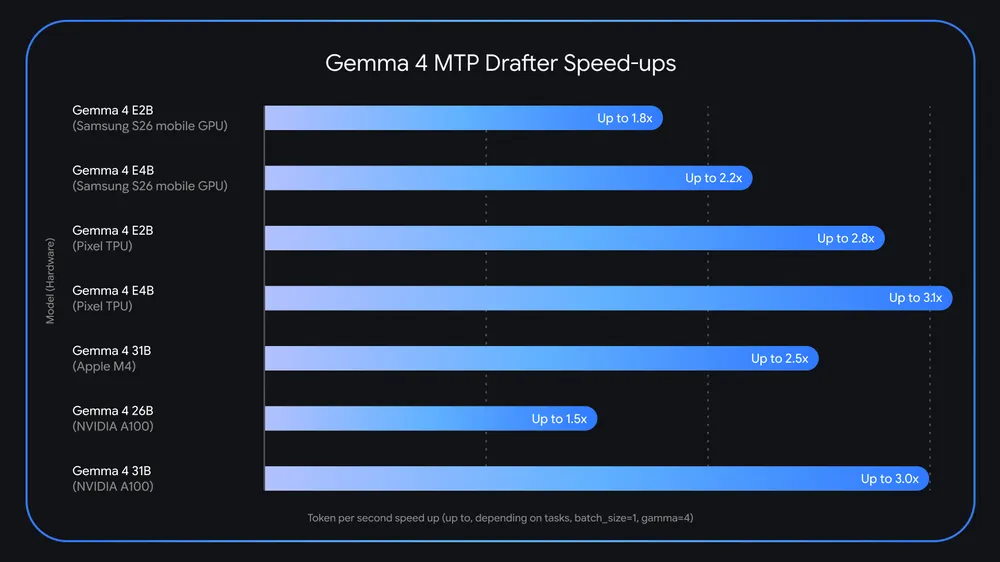
Google 的基础设施背景明显影响了 Gemma 4 的设计,因为该公司传统上会优化其 AI 系统,以利用定制的 TPU 芯片,这些芯片在大规模集群中运行,具有非凡的互连速度和内存带宽。这些专用处理器经过 Google 多年的机器学习研究而开发,可在 Gemini 充分发挥其潜力的数据中心环境中提供巨大的计算优势。然而,对于 Gemma 来说,工程理念发生了巨大的转变——模型的架构是为了在标准消费级硬件上高效运行。单个高性能 AI 加速器甚至可以以全精度成功运行最大的 Gemma 4 模型,无需外来的专用硬件即可提供可观的推理速度。
对于硬件预算较少的开发人员来说,量化技术提供了有效部署 Gemma 4 的额外途径。量化会降低模型权重和激活的数值精度,通常从 32 位浮点转换为较低精度的格式,例如 8 位整数或 4 位值。这种压缩方法不仅可以减少内存需求,还可以加速计算,甚至允许消费级 GPU 处理大量的 AI 模型。结合多令牌预测增强功能,量化的 Gemma 4 模型可以在笔记本电脑、边缘服务器和其他资源受限的环境中提供卓越的性能特征。这种可访问性代表了本地 AI 部署的分水岭,消除了历来限制资源充足组织的高级 AI 功能的传统障碍。

隐私考虑长期以来一直推动着人们对边缘人工智能系统的兴趣,而采用 MTP 技术的 Gemma 4 大大增强了这一价值主张。通过直接在本地硬件上启用高级人工智能推理,这些模型无需将敏感数据传输到谷歌或竞争提供商运营的云服务。事实证明,这种架构方法对于处理机密业务信息、受 HIPAA 法规保护的医疗保健数据或受 GDPR 和类似隐私框架约束的个人信息的组织特别有价值。在不离开本地计算环境的情况下执行复杂的人工智能任务的能力满足了监管要求,同时还通过更快的响应时间减少了延迟并改善了用户体验。
Google 决定根据 Apache 2.0 开源许可证重新授权 Gemma 4,这对于评估采用情况的开发人员和组织来说是另一个重要考虑因素。与 Google 最初的自定义 Gemma 许可证相比,Apache 2.0 许可证提供了明显更大的许可性,为商业使用、修改和分发提供了更广泛的自由。这一转变使 Gemma 4 与开源 AI 的行业最佳实践保持一致,并将模型定位为更广泛的开发者社区真正可访问的资源。许可变更有效地消除了法律上的模糊性,这些模糊性可能会使之前的商业部署变得复杂或对基本模型进行重大修改。对于评估人工智能基础设施战略的企业来说,这种更宽松的许可环境大大改善了围绕 Gemma 采用的风险计算。
多令牌预测的技术创新建立在推测执行和并行处理方面数十年的研究基础上。计算机科学早已认识到,对未来状态的智能预测可以显着提高系统效率,这是 CPU 分支预测、推测执行和许多其他优化技术中利用的原理。谷歌将这些概念应用于人工智能代币生成,展示了既定的计算机架构原理在应用于现代机器学习系统时如何解锁新功能。 MTP 技术本质上将这一经过验证的剧本应用于语言模型推理的顺序性质,将以前严格的顺序过程转变为具有重要并行化机会的过程。
多令牌预测起草者的性能基准测试无疑将成为未来几个月开发者社区的关键焦点。初步迹象表明,3 倍的速度提升代表了各种硬件配置和用例的实际性能提升,但实际结果可能会因特定模型大小、量化级别和目标硬件平台而异。对评估 MTP 技术感兴趣的开发人员已经可以开始尝试 Google 发布的实验模型,提供有价值的反馈,这些反馈可能会为未来的迭代和优化提供信息。事实证明,这个早期采用者社区生成的实际性能数据对于了解 MTP 技术在哪些方面可以带来最大的好处以及哪些方面可能值得进行额外的优化工作至关重要。
展望未来,改进的人工智能模型效率、更宽松的许可和突破性的推理优化技术的融合,使边缘人工智能成为以云为中心的人工智能架构日益引人注目的替代方案。随着世界各地的组织努力应对数据隐私法规、云服务成本和延迟要求,具有多令牌预测功能的 Gemma 4 等技术已成为其技术路线图的战略重要工具。谷歌对开源人工智能模型和性能改进的持续投资表明该公司认识到可本地部署的人工智能系统的技术优势和市场需求。随着生态系统的成熟以及开发人员利用这些功能构建创新应用程序,这些技术进步的影响可能会远远超出直接的开发人员社区,从而重塑人工智能在无数组织和用例中部署的方式。
来源: Ars Technica


