Google 的 Vids 平台借助人工智能驱动的 Veo 和 Lyria 模型进行了彻底变革

Google 的 Vids 平台通过集成 Veo 3.1 和 Lyria 模型进行了重大 AI 升级,提供增强的视频真实感、可定制的 AI 头像和无缝的 YouTube 共享。
Google 的视频平台经历了重大转型,集成了公司最新的人工智能视频和音频模型、Veo 3.1 和 Lyria。这些进步有望彻底改变用户在平台上创建和共享内容的方式。
Veo 3.1 模型于去年底首次部署在 Google 的 Gemini 平台中,现已集成到 Vids 中。此更新后的模型在真实性和一致性方面有了显着改进,使其成为对电影制作人和内容创作者等有吸引力的工具。
虽然 OpenAI 可能停止视频生成,但 Google 正在凭借自己的人工智能视频解决方案不断前进。该公司的视频平台现在让用户能够从各种可控化身中进行选择以出现在他们生成的视频中,从而为平台增添了新的个性化和创造力。
与OpenAI 的视频生成工作不同,Google 将其Vids 平台定位为面向广泛用户的工具,包括那些创建动画派对传单、商业宣传片或视频贺卡的用户。虽然视频平台免费提供,但用户需要订阅 AI 订阅才能生成更多视频。
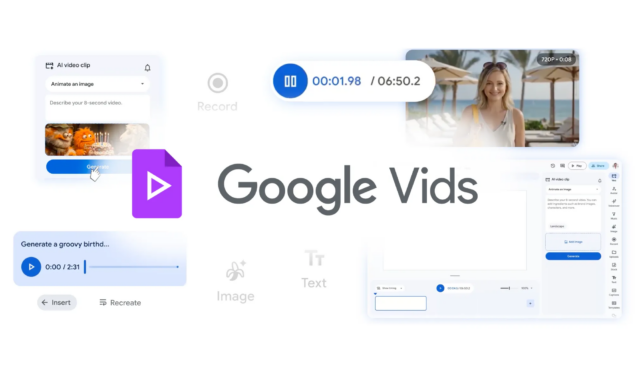
将 Veo 3.1 和 Lyria 模型集成到 Vids 平台中,标志着 Google 人工智能驱动的内容创建生态系统向前迈出了重要一步。凭借增强的真实感、可定制的头像和无缝的 YouTube 共享,该平台有望成为众多希望利用人工智能生成视频内容力量的创作者和企业的强大工具。
随着人工智能领域的不断发展,Google 对视频平台的战略投资表明了该公司致力于在这个快速变化的行业中保持领先地位。通过集成这些尖端的人工智能模型,视频平台将改变用户创建和共享视频内容的方式,为创造力和讲故事提供新的可能性。
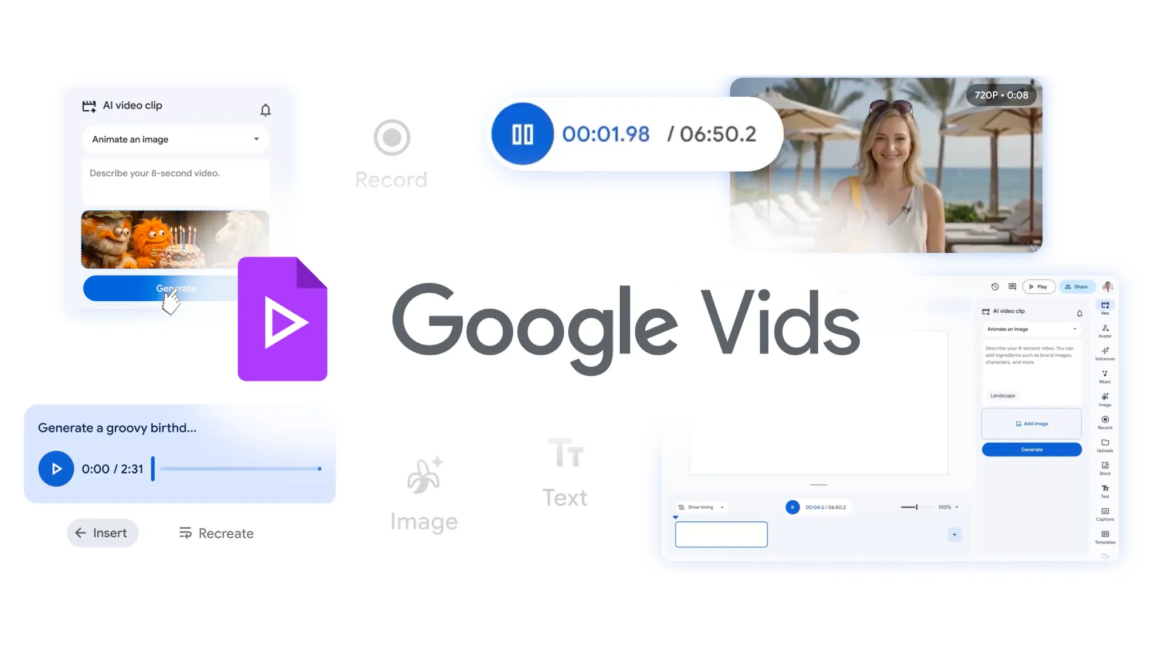
Vids 平台中的Veo 3.1 和 Lyria 模型集成明确表明Google 致力于提升其人工智能工具的功能。随着公司不断创新并突破视频生成和操作的可能性界限,Vids 平台有望成为创作者、企业和个人等越来越有价值的资源。
来源: Ars Technica


