Google's Gemma 4 AI Gets 3x Speed Boost

Google's Gemma 4 AI models now feature Multi-Token Prediction technology, delivering 3x faster performance. Learn how speculative decoding enhances local AI processing.
Google's Gemma 4 AI models have just received a significant performance upgrade that could transform how developers approach edge AI deployment. The search giant unveiled its Gemma 4 open-source AI models earlier this spring with impressive capabilities designed for local execution, and now the company is pushing the envelope even further with groundbreaking Multi-Token Prediction (MTP) technology. This innovative advancement promises to revolutionize inference speed, potentially delivering up to 3x faster token generation compared to conventional approaches. The introduction of MTP drafters represents a major leap forward in making powerful AI accessible and efficient for edge computing scenarios.
At the heart of this performance improvement lies a sophisticated technique called speculative decoding, which fundamentally changes how AI models generate text and other outputs. Rather than predicting one token at a time in a sequential manner, the Multi-Token Prediction system leverages advanced algorithms to intelligently forecast multiple future tokens simultaneously. This approach allows the system to "look ahead" and make educated guesses about what comes next in the generation process, dramatically reducing the computational overhead and latency associated with traditional token-by-token generation. Google's research team has engineered these experimental models to work seamlessly with Gemma's architecture, enabling developers to tap into this speed advantage without requiring significant modifications to their existing workflows.
The Gemma 4 models architecture is built upon the same foundational technology that powers Google's cutting-edge Gemini AI system, which represents the company's most advanced large language model offering. However, while Gemini is optimized for operation on Google's proprietary data centers and custom hardware, Gemma 4 has been specifically tuned and refined to operate efficiently on local hardware and edge devices. This localization strategy means developers no longer need to rely on cloud infrastructure or send sensitive data to remote servers, fundamentally changing the calculus for privacy-conscious organizations and those with stringent data governance requirements. The engineering approach demonstrates Google's commitment to democratizing advanced AI technology across diverse computing environments.
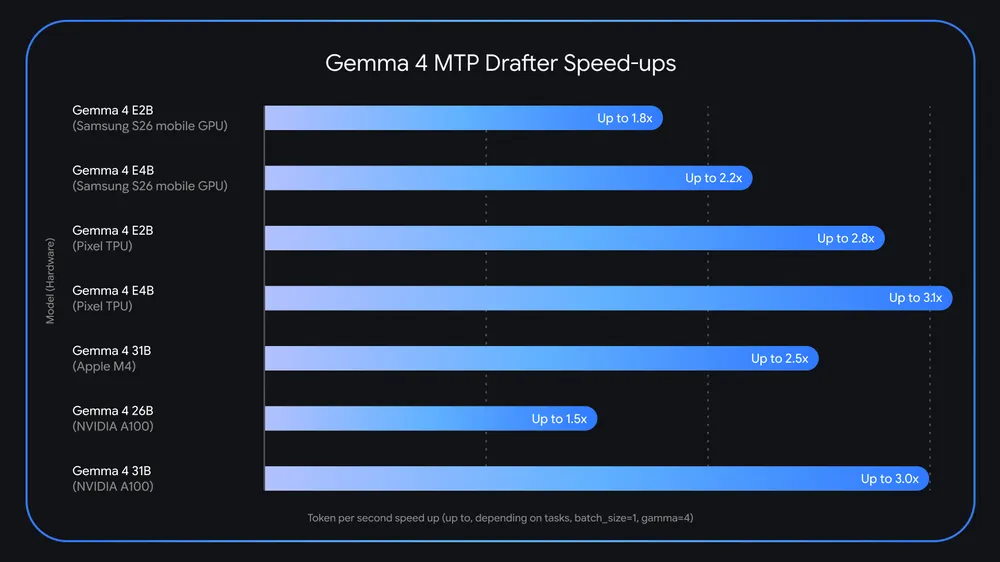
Google's infrastructure background clearly influences the design of Gemma 4, as the company has traditionally optimized its AI systems to leverage custom TPU chips that operate in massive clusters with extraordinary interconnect speeds and memory bandwidth. These specialized processors, developed over years of Google's machine learning research, provide enormous computational advantages in data center environments where Gemini reaches its full potential. For Gemma, however, the engineering philosophy shifts dramatically—the models are architected to operate efficiently on standard consumer-grade hardware. A single high-performance AI accelerator can successfully run even the largest Gemma 4 models at full precision, delivering respectable inference speeds without exotic specialized hardware.
For developers working with more modest hardware budgets, quantization techniques offer an additional pathway to deploying Gemma 4 effectively. Quantization reduces the numerical precision of model weights and activations, typically converting from 32-bit floating-point to lower-precision formats like 8-bit integers or 4-bit values. This compression approach not only reduces memory requirements but also accelerates computation, allowing even consumer-grade GPUs to handle substantial AI models. Combined with the Multi-Token Prediction enhancement, quantized Gemma 4 models could deliver remarkable performance characteristics on laptops, edge servers, and other resource-constrained environments. This accessibility represents a watershed moment for local AI deployment, removing traditional barriers that have historically limited advanced AI capabilities to well-resourced organizations.

Privacy considerations have long driven interest in edge AI systems, and Gemma 4 with MTP technology amplifies this value proposition considerably. By enabling advanced AI inference directly on local hardware, these models eliminate the need to transmit sensitive data to cloud services operated by Google or competing providers. This architectural approach proves particularly valuable for organizations handling confidential business information, healthcare data protected by HIPAA regulations, or personal information subject to GDPR and similar privacy frameworks. The ability to perform sophisticated AI tasks without leaving the local computing environment addresses regulatory requirements while also reducing latency and improving user experience through faster response times.
Google's decision to relicense Gemma 4 under the Apache 2.0 open-source license represents another crucial consideration for developers and organizations evaluating adoption. The Apache 2.0 license provides significantly greater permissiveness compared to Google's original custom Gemma license, offering broader freedoms for commercial use, modification, and distribution. This shift aligns Gemma 4 with industry best practices for open-source AI and positions the models as genuinely accessible resources for the broader developer community. The licensing change effectively removes legal ambiguity that might have previously complicated commercial deployments or significant modifications to the base models. For enterprises evaluating their AI infrastructure strategy, this more permissive licensing landscape substantially improves the risk calculus around Gemma adoption.
The technical innovation of Multi-Token Prediction builds upon decades of research in speculative execution and parallel processing. Computer science has long recognized that intelligent prediction of future states can dramatically improve system efficiency, a principle exploited in CPU branch prediction, speculative execution, and numerous other optimization techniques. Google's application of these concepts to AI token generation demonstrates how established computer architecture principles can unlock new capabilities when applied to modern machine learning systems. The MTP technology essentially applies this proven playbook to the sequential nature of language model inference, transforming what was previously a strictly sequential process into one with significant parallelization opportunities.
Performance benchmarking of the Multi-Token Prediction drafters will undoubtedly become a critical focus for the developer community in coming months. Initial indications suggest that the 3x speed improvement represents realistic performance gains across a variety of hardware configurations and use cases, though actual results may vary depending on specific model sizes, quantization levels, and target hardware platforms. Developers interested in evaluating MTP technology can already begin experimenting with the experimental models released by Google, providing valuable feedback that will likely inform future iterations and optimizations. The real-world performance data generated by this early adopter community will prove essential for understanding where MTP technology delivers the most substantial benefits and where additional optimization work might prove worthwhile.
Looking forward, the convergence of improved AI model efficiency, more permissive licensing, and groundbreaking inference optimization techniques positions edge AI as an increasingly compelling alternative to cloud-centric AI architectures. As organizations worldwide grapple with data privacy regulations, cloud service costs, and latency requirements, technologies like Gemma 4 with Multi-Token Prediction become strategically important tools for their technology roadmaps. Google's continued investment in open-source AI models and performance improvements suggests the company recognizes both the technical merit and market demand for locally-deployable AI systems. As the ecosystem matures and developers build innovative applications leveraging these capabilities, the impact of these technological advances will likely extend far beyond the immediate developer community to reshape how AI gets deployed across countless organizations and use cases.
Source: Ars Technica


