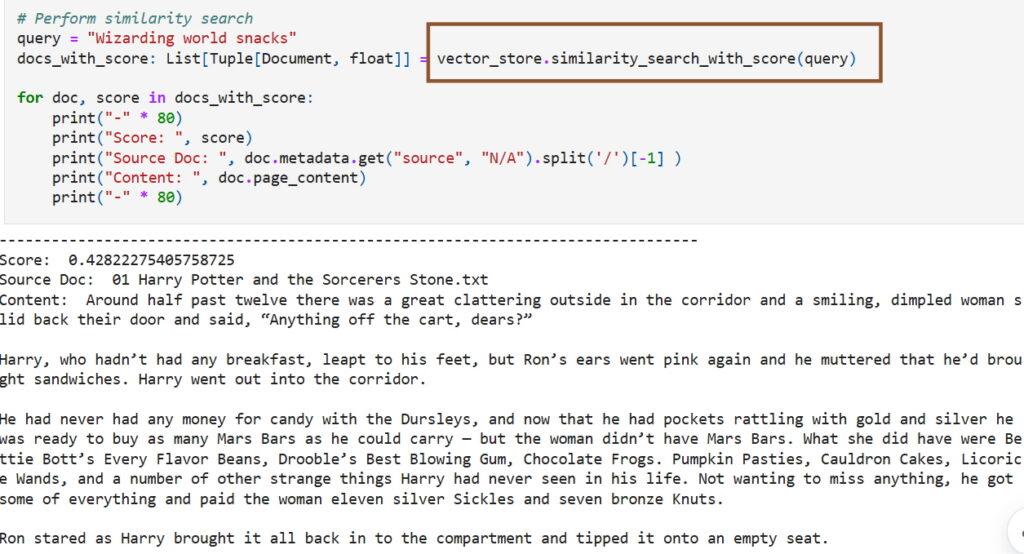
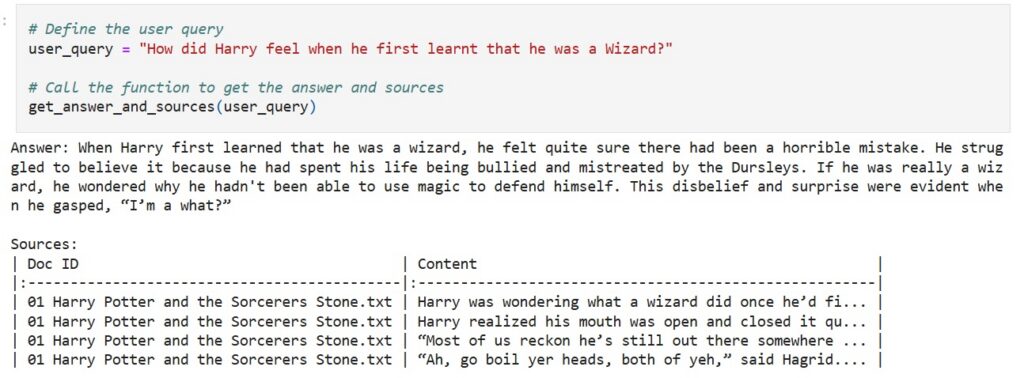
Microsoft Removes AI Guide Using Pirated Harry Potter

Microsoft deleted a controversial blog post that instructed developers how to train AI models using pirated Harry Potter books after facing community backlash.
Technology giant Microsoft has removed a controversial blog post that appeared to encourage developers to use pirated Harry Potter books for training artificial intelligence models. The deletion came after intense criticism from the developer community, particularly following discussions on a popular Hacker News forum thread that highlighted the problematic nature of the guidance. The incident raises significant questions about corporate responsibility in AI training practices and intellectual property rights in the rapidly evolving artificial intelligence landscape.
The now-deleted blog post, which remains accessible through web archives, was authored by Pooja Kamath, a senior product manager at Microsoft who has been with the company for over a decade. Published in November 2024, the article was designed to showcase Microsoft's new Azure SQL DB capabilities that integrate with LangChain and large language models. According to her professional profile, Kamath continues to work at Microsoft despite the controversy surrounding her blog post, and the company selected her specifically to promote this new generative AI feature integration.
The blog post positioned itself as a demonstration of how developers could easily incorporate generative AI features into their applications using Microsoft's cloud infrastructure. The controversial guidance suggested that developers could accomplish this integration with minimal coding effort, requiring only a few lines of code to connect Azure SQL DB with popular AI frameworks. This streamlined approach was presented as a significant advancement in making AI development more accessible to a broader range of developers and organizations.

What sparked the most intense criticism was the blog's recommendation to use Harry Potter books as training data for AI models. The post described this approach as utilizing a "well-known dataset" that would provide "engaging and relatable examples" capable of resonating with a wide audience. Critics argued that this guidance effectively encouraged developers to use copyrighted material without proper authorization, potentially violating intellectual property laws and setting a dangerous precedent for AI training practices across the industry.
The backlash intensified when members of the Hacker News community discovered the blog post and began discussing its implications. The forum thread quickly gained traction as developers, legal experts, and AI researchers weighed in on the problematic nature of Microsoft's guidance. Many participants expressed concern that a major technology corporation was seemingly endorsing the use of pirated content for commercial AI development purposes, particularly given the ongoing legal battles surrounding AI training data and copyright infringement.
Industry observers noted that this incident occurs against the backdrop of numerous high-profile legal challenges facing AI companies over their training data practices. Publishers, authors, and content creators have increasingly pursued legal action against tech giants who allegedly used copyrighted material without permission to train their large language models. The Harry Potter series, owned by Warner Bros. and author J.K. Rowling's estate, represents exactly the type of valuable intellectual property that rights holders are actively protecting through litigation.

The controversy also highlights broader questions about corporate governance and oversight in AI development initiatives. Critics questioned how such guidance could be published on an official Microsoft development blog without apparently undergoing proper legal review. The incident suggests potential gaps in the company's content approval processes, particularly for materials that could expose the corporation and its customers to legal liability related to copyright infringement claims.
Microsoft's decision to delete the blog post rather than modify or clarify its content indicates the company recognized the severity of the situation. However, the removal has not eliminated the archived versions of the post, which continue to circulate online and serve as evidence of the original guidance. This situation demonstrates the permanent nature of digital content and the challenges companies face when attempting to retract problematic material from the internet.
The timing of this incident is particularly significant given the current regulatory environment surrounding AI development and intellectual property rights. Governments worldwide are developing new frameworks for governing AI training practices, and incidents like this could influence future regulations. The European Union's AI Act and similar legislation in other jurisdictions specifically address issues related to training data and copyright compliance, making Microsoft's guidance potentially problematic from a regulatory compliance perspective.
Legal experts have noted that the blog post's recommendations could have exposed both Microsoft and its customers to significant liability. Companies that followed the guidance and used pirated Harry Potter content for AI training could face copyright infringement lawsuits from rights holders. The potential damages in such cases could be substantial, particularly if the trained AI models were used for commercial purposes or generated content that competed with official Harry Potter products.
The incident also raises questions about the broader culture within Microsoft's AI development teams and their understanding of intellectual property law. The fact that a senior product manager with over a decade of experience at the company authored such guidance suggests potential systematic issues with legal awareness and training. This has prompted calls for enhanced education and oversight mechanisms within the organization to prevent similar incidents in the future.
Industry analysts have pointed out that this controversy could damage Microsoft's reputation among potential enterprise customers who prioritize legal compliance and risk management. Many large organizations are hesitant to adopt AI solutions that could expose them to copyright infringement claims, and incidents like this may increase their concerns about working with Microsoft's AI platforms and services.
The removal of the blog post also highlights the ongoing tension between the AI industry's need for training data and the rights of content creators. While AI companies argue that large datasets are essential for developing effective models, publishers and authors contend that their intellectual property rights must be respected. This fundamental disagreement continues to generate legal battles and regulatory scrutiny across multiple jurisdictions worldwide.
Moving forward, this incident is likely to influence how technology companies approach AI training guidance and documentation. The controversy demonstrates the importance of careful legal review for all public-facing content related to AI development, particularly materials that provide specific implementation guidance to developers. Companies may need to invest additional resources in legal oversight and compliance training to avoid similar situations.
The Microsoft Harry Potter AI training controversy serves as a cautionary tale about the intersection of artificial intelligence development and intellectual property law. As the AI industry continues to evolve rapidly, incidents like this underscore the critical importance of balancing innovation with respect for existing legal frameworks and the rights of content creators. The long-term implications of this controversy may extend far beyond Microsoft, potentially influencing industry practices and regulatory approaches to AI training data governance.
Source: Ars Technica


